
@Controller
class BankController {
@PostMapping("/users/register")
public void register(RegistrationForm form) {
validate(form);
riskCheck(form);
openBankAccount(form);
// etc..
}
}
Java Microservices: A Practical Guide
Last updated on November 22, 2020 - 19 comments
Star me on GitHub →You can use this guide to understand what Java microservices are, how you architect and build them. Also: A look at Java microservice libraries & common questions.
[Editor’s note: At nearly 7,000 words, you probably don’t want to try reading this on a mobile device. Bookmark it and come back later.]
Java Microservices: The Basics
To get a real understanding of Java microservices, it makes sense to start with the very basics: The infamous Java monolith, what it is and what its advantages or disadvantages are.
What is a Java monolith?
Imagine you are working for a bank or a fintech start-up. You provide users a mobile app, which they can use to open up a new bank account.
In Java code, this will lead to a controller class that looks, simplified, like the following.
You’ll want to:
-
Validate the registration form.
-
Do a risk check on the user’s address to decide if you want to give him a bank account or not.
-
Open up the bank account
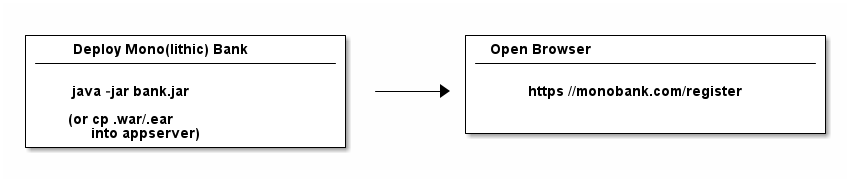
Your BankController class will be packaged up, with all your other source code, into a bank.jar or bank.war file for deployment: A good, old monolith, containing all the code you need for your bank to run. (As a rough pointer, initially your .jar/.war file will have a size in the range of 1-100MB).
On your server, you then simply run your .jar file - that’s all you need to do to deploy Java applications.
What is the problem with Java monoliths?
At its core, there’s nothing wrong with a Java monolith. It is simply that project experience has shown that, if you:
-
Let many different programmers/teams/consultancies…
-
Work on the same monolith under high pressure and unclear requirements…
-
For a couple of years…
Then your small bank.jar file, turns into a gigabyte large code monster, that everyone fears deploying.
How to get the Java monolith smaller?
This naturally leads to the question of how to get the monolith smaller. For now, your bank.jar runs in one JVM, one process on one server. Nothing more, nothing less.
Now you could come up with the idea to say: Well, the risk check service is being used by other departments in my company and it doesn’t really have anything to do with my Mono(lithic) Bank domain, so we could try and cut it out of the monolith and deploy it as its own product, or more technically, run it as its own Java process.
What is a Java Microservice?
In practical terms, this means that instead of calling the riskCheck() method inside your BankController, you will move that method/bean with all its helper classes to its own Maven/Gradle project, put it under source control and deploy it independently from your banking monolith.
That whole extraction process does not make your new RiskCheck module a microservice per se and that is because the definition of microservices is open for interpretation (which leads to a fair amount of discussion in teams and companies).
-
Is it micro if it only has 5-7 classes inside?
-
Are 100 or 1000 classes still micro?
-
Has it even got anything to do with the number of classes?
Instead of theorizing about it, we’ll keep things pragmatic and do two things:
-
Call all separately deployable services microservices - independent of size or domain boundaries.
-
Focus on the important topic of inter-service communication, because your microservices need ways to talk to each other.
So, to sum up: Before you had one JVM process, one Banking monolith. Now you have a banking monolith JVM process and a RiskCheck microservice, which runs in its own JVM process. And your monolith now has to call that microservice for risk checks.
How do you do that?
How to communicate between Java Microservices?
You basically have two choices: synchronous communication or asynchronous communication.
(HTTP)/REST - Synchronous Communication
Synchronous microservice communication is usually done via HTTP and REST-like services that return XML or JSON - though this is by no means required (have a look at Google’s Protocol Buffers for example).
Use REST communication when you need an immediate response, which we do in our case, as risk-checking is mandatory before opening an account: No risk check, no account.
Tool-wise, check out Which libraries are the best for synchronous Java REST calls?.
Messaging - Asynchronous Communication
Asynchronous microservice communication is usually done through messaging with a JMS implementation and/or with a protocol like AMQP. Usually, because the number of, for example, email/SMTP-driven integrations is not to be underestimated in practice.
Use it when you do not need an immediate response, say the users presses the 'buy-now' button and you want to generate an invoice, which certainly does not have to happen as part of the user’s purchase request-response cycle.
Tool-wise, check out Which brokers are the best for asynchronous Java messaging?.
Example: Calling REST APIs in Java
Assuming we chose to go with synchronous microservice communication, our Java code from above would then look something like this on a low-level. Low-level, because for microservice communication you usually create client libraries, that abstract the actual HTTP calls away from you.
@Controller
class BankController {
@Autowired
private HttpClient httpClient;
@PostMapping("/users/register")
public void register(RegistrationForm form) {
validate(form);
httpClient.send(riskRequest, responseHandler());
setupAccount(form);
// etc..
}
}Looking at the code it becomes clear, that you now must deploy two Java (micro)services. Your Bank and your RiskCheck service. You are going to end up with two JVMs, two processes. The graphic from before will look like this:
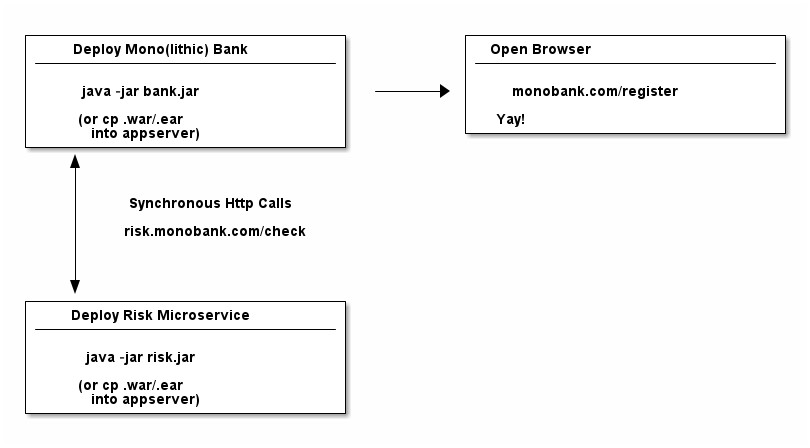
That’s all you need to develop a Java Microservices project: Build and deploy smaller pieces (.jar or .war files), instead of one large piece.
But that leaves the question: How exactly do you cut or setup those microservices? What are these smaller pieces? What is the right size?
Let’s do a reality check.
Java Microservice Architecture
In practice, there’s various ways that companies try to design or architect Microservice projects. It depends on if you are trying to turn an existing monolith into a microservices project, or if you are starting out with a new Greenfield project.
From Monolith to Microservices
One rather organic idea is to break microservices out of an existing monolith. Note, that "micro" here does not actually mean that the extracted services themselves will, indeed, be micro - they could still be quite large themselves.
Let’s look at some theory.
The Idea: Break a Monolith into Microservices
Legacy projects lend themselves to a microservices approach. Mainly, for three reasons:
-
They are often hard to maintain/change/extend.
-
Everyone, from developers, ops to management wants to make things simpler wants stuff to be simpler.
-
You have (somewhat) clear domain boundaries, that means: You know what your software is supposed to do.
This means you can have a look at your Java bank monolith and try to split it along domain boundaries - a sensible approach.
-
You could conclude that there should be an 'Account Management' microservice, that handles user data like names, addresses, phone numbers.
-
Or the aforementioned 'Risk Module', that checks user risk levels and which could be used by many other projects or even departments in your company.
-
Or an invoicing module, that sends out invoices via PDF or actual mail.
Reality: Let someone else do it
While this approach definitely looks good on paper and UML-like diagrams, it has its drawbacks. Mainly, you need very strong technical skills to pull it off. Why?
Because there is a huge difference between understanding that it would be a good thing to extract the, say, highly coupled account management module out of your monolith and doing it (properly).
Most enterprise projects reach the stage where developers are scared to, say, upgrade the 7-year-old Hibernate version to a newer one, which is just a library update but a fair amount of work trying to make sure not to break anything.
Those same developers are now supposed to dig deep into old, legacy code, with unclear database transaction boundaries and extract well-defined microservices? Possible, but often a real challenge and not solvable on a whiteboard or in architecture meetings.

This is already the first time in this article, where a quote from @simonbrown on Twitter fits in:
I'll keep saying this ... if people can't build monoliths properly, microservices won't help.
Greenfield Project Microservice Architecture
Things look a bit different when developing new, greenfield Jav aprojects. Now, those three points from above look a bit different:
-
You are starting with a clean slate, so there’s no old baggage to maintain.
-
Developers would like things to stay simple in the future.
-
The issue: You have a much foggier picture of domain boundaries: You don’t know what your software is actually supposed to do (hint: agile ;) )
This leads to various ways that companies try and tackle greenfield Java microservices projects.
Technical Microservice Architecture
The first approach is the most obvious for developers, although the one highly recommended against. Props to Hadi Hariri for coming up with the "Extract Microservice" refactoring in IntelliJ.

While the following example is oversimplified to the extreme, actual implementations seen in real projects are unfortunately not too far off.
Before Microservices
@Service
class UserService {
public void register(User user) {
String email = user.getEmail();
String username = email.substring(0, email.indexOf("@"));
// ...
}
}With a substring Java microservice
@Service
class UserService {
@Autowired
private HttpClient client;
public void register(User user) {
String email = user.getEmail();
// now calling the substring microservice via http
String username = httpClient.send(substringRequest(email), responseHandler());
// ...
}
}So, you are essentially wrapping a Java method call into a HTTP call, with no obvious reasons to do so. One reason, however, is: Lack of experience and trying to force a Java microservices approach.
Recommendation: Don’t do it.
Workflow Oriented Microservice Architecture
The next common approach is, to module your Java microservices after your workflow.
Real-Life example: In Germany, when you go to a (public) doctor he needs to record your appointment in his health software CRM.
To get paid from the insurance he will send in your treatment data and that of all other patients he treated to an intermediary via XML.
The intermediary will have a look at that XML file and (simplified):
-
Try and validate the file that it is proper XML
-
Try and validate it for plausibility: did it make sense that a 1 year old got three tooth cleanings in a day from a gynecologist?
-
Enhance the XML with some other bureaucratic data
-
Forward the XML to the insurance to trigger payments
-
And model the whole way back to the doctor, including a "success" message or "please re-send that data entry again - once it makes sense"
If you now try and model this workflow with microservives, you will end up with at least.
Note: Communication between Microservices is irrelevant in this example, but could well be done asynchronously with a message broker like RabbitMQ, as the doctor does not get immediate feedback, anyway.

Again, this is something that looks good on paper, but immediately leads to several questions:
-
Do you feel the need to deploy six applications to process 1 xml file?
-
Are these microservices really independent from each other? They can be deployed independently from each other? With different versions and API schemes?
-
What does the plausibility-microservice do if the validation microservice is down? Is the system then still running?
-
Do these microservices now share the same database (they sure need some common data in a database table) or are you going to take the even bigger hammer of giving them all their own database?
-
And a ton of other infrastructure/operations questions.
Interestingly, for some architects the above diagram reads simpler, because every service now has its exact, well-defined purpose. Before, it looked like this scary monolith:

While arguments can be made about the simplicity of those diagrams, you now definitely have these additional operational challenges to solve.
You…
-
Don’t just need to deploy one application, but at least six.
-
Might even need to deploy multiple databases, depending on how far you want to take your microservice architecture.
-
Have to make sure that every system is online, healthy and working.
-
Have to make sure that your calls between microservices are actually resilient (see How to make a Java microservice resilient?).
-
And everything else this setup implies - from local development setups to integration testing.
Recommendation:
Unless:
-
you are Netflix (you are not)…
-
you have super-strong operation skills: you open up your development IDE, which triggers a chaos monkey that DROPs your production database which easily auto-recovers in 5 seconds.
-
or you feel like @monzo in giving 1500 microservices a try, simply because you can.
→ Don’t do it.
In less hyperbole, though.
Trying to model microservices after domain boundaries is a very sensible approach. But a domain boundary (say user management vs invoicing) does not mean taking a single workflow and splitting it up into its tiniest individual pieces (receive XML, validate XML, forward XML).
Hence, whenever you are starting out with a new Java microservices project and the domain boundaries are still very vague, try to keep the size of your microservices on the lower end. You can always add more modules later on.
And make sure that you have exceptionally strong DevOps skills across your team/company/division to support your new infrastructure.
Polyglot or Team Oriented Microservice Architecture
There is a third, almost libertarian approach to developing microservices: Giving your teams or even individuals the possibility to implement user stories with as many languages or microservices they want (marketing term: polyglot programming).
So the XML Validation service above could be written in Java, while the Plausibility Microservice is written in Haskell (to make it mathematically sound) and the Insurance Forwarding Microservice should be written in Erlang (because it really needs to scale ;) ).
What might look like fun from a developer’s perspective (developing a perfect system with your perfect language in an isolated setting) is basically never what an organization wants: Homogenization and standardization.
That means a relatively standardized set of languages, libraries and tools so that other developers can keep maintaining your Haskell microservice in the future, once you are off to greener pastures.

What’s interesting: Historically standardization went way too far. Developers in big Fortune 500 companies were sometimes not even allowed to use Spring, because it was 'not in the company’s technology blueprint'. But going full-on polyglot is pretty much the same thing, just the other side of the same coin.
Recommendation : If you are going polyglot, try smaller diversity in the same programming language eco-system. Example: Kotlin and Java (JVM-based with 100% compatibility between each other), not Haskell and Java.
Deploying and Testing Java Microservices
It helps to have a quick look back at the basics, mentioned at the beginning of this article. Any server-side Java program, hence also any microservice, is just a .jar/.war file.
And there’s this one great thing about the Java ecosystem, or rather the JVM: You write your Java code once, you can run it basically on any operating system you want provided you didn’t compile your code with a newer Java version than your target JVM’s versions).
It’s important to understand this, especially when it comes to topics like Docker, Kubernetes or (shiver) The Cloud. Why? Let’s have a look at different deployment scenarios:
A bare minimum Java microservice deployment example
Continuing with the bank example, we ended up with our monobank.jar file (the monolith) and our freshly extracted riskengine.jar (the first microservice).
Let’s also assume that both applications, just like any other application in the world, need a .properties file, be it just the database url and credentials.
A bare minimum deployment could hence consist of just two directories, that look roughly like this:
-r-r------ 1 ubuntu ubuntu 2476 Nov 26 09:41 application.properties
-r-x------ 1 ubuntu ubuntu 94806861 Nov 26 09:45 monobank-384.jar
ubuntu@somemachine:/var/www/www.monobank.com/java$ java -jar monobank-384.jar
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
...-r-r------ 1 ubuntu ubuntu 2476 Nov 26 09:41 application.properties
-r-x------ 1 ubuntu ubuntu 94806861 Nov 26 09:45 risk-engine-1.jar
ubuntu@someothermachine:/var/www/risk.monobank.com/java$ java -jar risk-engine-1.jar
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
...This leaves open the question: How do you get your .properties and .jar file onto the server?
Unfortunately, there’s a variety of alluring answers to that question.
How to use Build Tools, SSH & Ansible for Java microservice deployments
The boring, but perfectly fine answer to Java microservice deployments is how admins deployed any Java server-side program in companies in the past 20 years. With a mixture of:
-
Your favorite build tool (Maven, Gradle)
-
Good old SSH/SCP for copying your .jars to servers
-
Bash scripts to manage your deployment scripts and servers
-
Or even better: some Ansible scripts.
If you are not fixated on creating a breathing cloud of ever auto-load-balancing servers, chaos monkeys nuking your machines, or the warm and fuzzy-feeling of seeing ZooKeeper’s leader election working, then this setup will take you very far.
Oldschool, boring, but working.
How to use Docker for Java microservice deployments
Back to the alluring choices. A couple of years ago, Docker or the topic of containerization hit the scene.
If you have no previous experience with it, this is what it is all about for end-users or developers:
-
A container is (simplified) like a good old virtual machine, but more lightweight. Have a look at this Stackoverflow answer to understand what lightweight means in this context.
-
A container guarantees you that it is portable, it runs anywhere. Does this sound familiar?
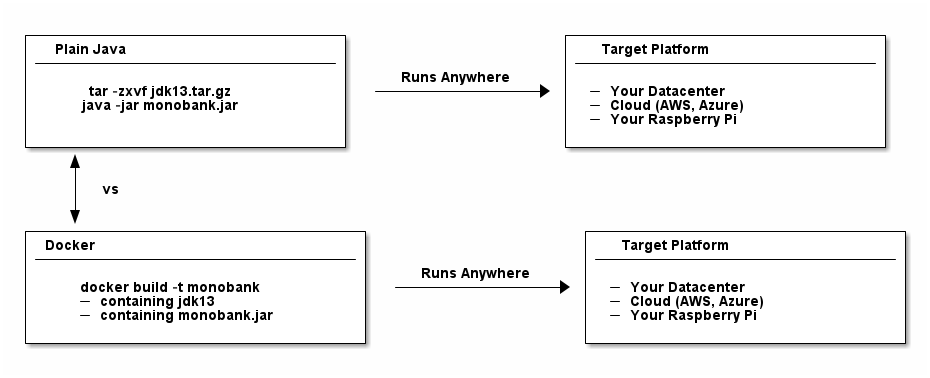
Interestingly, with the JVM’s portability and backwards compatibility this doesn’t sound like major benefits. You could just download a JVM.zip on any server, Raspberry Pi (or even mobile phone), unzip it and run any .jar file you want.
It looks a bit different for languages like PHP or Python, where version incompatibilities or deployment setups historically were more complex.
Or if your Java application depends on a ton of other installed services (with the right version numbers): Think of a database like Postgres or key-value store like Redis.
So, Docker’s primary benefit for Java microservices, or rather Java applications lies in:
-
Setting up homogenized test or integration environments, with tools like Testcontainers.
-
Making complex deployables "simpler" to install. Take the Discourse forum software. You can install it with one Docker image, that contains everything you need: From the Discourse software written in Ruby, to a Postgres database, to Redis and the kitchen sink.
If your deployables look similar or you want to run a nice, little Oracle database on your development machine, give Docker a try.
So, to sum things up, instead of simply scp’ing a .jar file, you will now:
-
Bundle up your jar file into a Docker image
-
Transfer that docker image to a private docker registry
-
Pull and run that image on your target platform
-
Or scp the Docker image directly to your prod system and run it
How to use Docker Swarm or Kubernetes for Java microservice deployments
Let’s say you are giving Docker a try. Every time you deploy your Java microservice, you now create a Docker image which bundles your .jar file. You have a couple of these Java microservices and you want to deploy these services to a couple of machines: a cluster.
Now the question arises: How do you manage that cluster, that means run your Docker containers, do health checks, roll out updates, scale (brrrr)?
Two possible answers to that question are Docker Swarm and Kubernetes.
Going into detail on both options is not possible in the scope of this guide, but the reality takeaway is this: Both options in the end rely on you writing YAML files (see Not a question: Yaml Indentation Tales) to manage your cluster. Do a quick search on Twitter if you want to know what feelings that invokes in practice.
So the deployment process for your Java microservices now looks a bit like this:
-
Setup and manage Docker Swarm/Kubernetes
-
Everything from the Docker steps above
-
Write and execute YAML until your eyes bleed things are working
How to test Java microservices
Let’s assume you solved deploying microservices in production, but how do you integration test your n-microservices during development? To see if a complete workflow is working, not just the single pieces?
In practice, you’ll find three different ways:
-
With a bit of extra work (and if you are using frameworks like Spring Boot), you can wrap all your microservices into one launcher class, and boot up all microservices with one Wrapper.java class - depending if you have enough memory on your machine to run all of your microservices.
-
You can try to replicate your Docker Swarm or Kubernetes setup locally.
-
Simply don’t do integration tests locally anymore. Instead have a dedicated DEV/TEST environment. It’s what a fair numbers of teams actually do, succumbing to the pain of local microservice setups.
Furthermore, in addition to your Java microservices, you’ll likely also need an up and running message broker (think: ActiveMQ or RabbitMQ) or maybe an email server or any other messaging component that your Java microservices need to communicate with each other.
This leads to a fair amount of underestimated complexity on the DevOps side. Have a look at Microservice Testing Libraries to mitigate some of that pain.
In any case, this complexity leads us to common Microservice issues:
Common Java Microservice Questions
Let’s have a look at Java specific microservices issues, from more abstract stuff like resilience to specific libraries.
How to make a Java microservice resilient?
To recap, when building microservices, you are essentially swapping out JVM method calls with synchronous HTTP calls or asynchronous messaging.
Whereas a method call execution is basically guaranteed (with the exception of your JVM exiting abruptly), a network call is, by default, unreliable.
It could work, it could also not work for various reasons: From the network being down or congested, to a new firewall rule being implemented to your message broker exploding.
To see what implications that has, let’s have a look at an exemplary BillingService example.
HTTP/REST Resilience Patterns
Say customers can buy e-books on your companies' website. For that, you just implemented a billing microservice, that your webshop can call to generate the actual PDF invoices.
For now, we’ll do that call synchronously, via HTTP. (It would make more sense to call that service asynchronously, because PDF generation doesn’t have to be instant from a user’s perspective. But we want to re-use this very example in the next section and see the differences.)
@Service
class BillingService {
@Autowired
private HttpClient client;
public void bill(User user, Plan plan) {
Invoice invoice = createInvoice(user, plan);
httpClient.send(invoiceRequest(user.getEmail(), invoice), responseHandler());
// ...
}
}Think about what kind of possible results that HTTP call could have. To generalize, you will end up with three possible results:
-
OK: The call went through and the invoice got created successfully.
-
DELAYED: The call went through but took an unusually long amount of time to do so.
-
ERROR: The call did not go through, maybe because you sent an incompatible request, or the system was down.
Handling errors, not just the happy-cases, is expected for any program. It is the same for microservices, even though you have to take extra care to keep all of your deployed API versions compatible, as soon as you start with individual microservice deployments and releases.
And if you want to go full-on chaos-monkey, you will also have to live with the possibility that your servers just get nuked during request processing and you might want the request to get re-routed to another, working instance.

An interesting 'warning' case is the delayed case. Maybe the responding’s microservice hard-disk is running full and instead of 50ms, it takes 10 seconds to respond. This can get even more interesting when you are experiencing a certain load, so that the unresponsiveness of your BillingService starts cascading through your system. Think of a slow kitchen slowly starting the block all the waiters of a restaurant.
This section obviously cannot give in-depth coverage on the microservice resilience topic, but serves as a reminder for developers that this is something to actually tackle and not ignore until your first release (which from experience, happens more often than it should)
A popular library that helps you think about latency and fault tolerance, is Netflix’s Hystrix. Use its documentation to dive more into the topic.
Messaging Resilience Patterns
Let’s take a closer look at asynchronous communication. Our BillingService code might now look something like this, providing we use Spring and RabbitMQ for our messaging.
To create an invoice, we now send a message to our RabbitMQ message broker, which has some workers waiting for new messages. These workers create the PDF invoices and send them out to the respective users.
@Service
class BillingService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void bill(User user, Plan plan) {
Invoice invoice = createInvoice(user, plan);
// converts the invoice to,for example, json and uses it as the message's body
rabbitTemplate.convertAndSend(exchange, routingkey, invoice);
// ...
}
}Now the potential error cases look a bit different, as you don’t get immediate OK or ERROR responses anymore, like you did with synchronous HTTP communication. Instead, you’ll roughly have these three error cases:
-
Was my message delivered and consumed by a worker? Or did it get lost? (The user gets no invoice).
-
Was my message delivered just once? Or delivered more than once and only processed exactly once? (The user would get multiple invoices).
-
Configuration: From "Did I use the right routing-keys/exchange names", to is "my message broker setup and maintained correctly or are its queues overflowing?" (The user gets no invoice).
Again, it is not in the scope of this guide to go into detail on every single asynchronous microservice resilience pattern. More so, it is meant as pointers in the right direction, especially as it also depends on the actual messaging technology you are using. Examples:
-
If you are using JMS implementations, like ActiveMQ, you could want to trade speed for the guarantees of two-phase (XA) commits.
-
If you are using RabbitMQ you at least want to make sure to have read and understood this guide and then think hard about acknowledgements, confirms and message reliability in general.
-
And also have someone with experience in setting up e.g. Active or RabbitMQ servers and configuring them properly, especially when used in combination with clustering and Docker (network splits, anyone? ;) )
Which Java microservice framework is the best?
On one hand you have established and very popular choices like Spring Boot, which makes it very easy to build .jar files that come with an embedded web server like Tomcat or Jetty and that you can immediately run anywhere. A perfect fit for building microservice applications.
Recently though, and partially inspired by parallel developments like reactive programming, Kubernetes or GraalVM, a couple of, dedicated microservice frameworks have arisen.
In the end, you will have to make your own choice, but this article can give some, maybe unconventional, guidance:
With the exception of Spring Boot, all microservices frameworks generally market themselves as blazingly fast, monumentally quick startup time, low memory footprint, able to scale indefinitely, with impressive graphs comparing themselves against the Spring Boot behemoth or against each other.
This is clearing hitting a nerve with developers who are maintaining legacy projects that sometimes take minutes to boot-up or cloud-native developers who want to start-stop as many micro-containers as they now can or want they need in 50ms.

The issue, however, is that (artificial) bare metal startup times and re-deploy times barely have an effect on a project’s overall success, much less so than a strong framework ecosystem, strong documentation, community and strong developer skills.
You’ll have to look at it this way.
If until now:
-
You let your ORMs run rampage and generate hundreds of queries for simple workflows.
-
You needed endless gigabytes for your moderately complex monolith to run.
-
You added so much code and complexity that (disregarding potentially slow starters like Hibernate) your application now need minutes to boot up.
Then adding additional Microservice challenges (think: resilience, network, messaging, DevOps, infrastructure) on top will have a much heavier impact on your project, than booting up an empty hello world. And for hot redeploys during development, you finally might want to look into solutions like JRebel or DCEVM.
To go back to Simon Brown’s quote: If people cannot build (fast & efficient) monoliths, they will be having a hard time building (fast & efficient) microservices - no matter the framework.
So, choose your framework wisely.
Which libraries are the best for synchronous Java REST calls?
On to the more practical aspects of calling HTTP REST APIs. On the low-level technical side, you are probably going to end up with one of the following HTTP client libraries:
Java’s own HttpClient (since Java 11), Apache’s HttpClient or OkHttp.
Note that I am saying 'probably' here because there is a gazillion other ways as well, from good old JAX-RS clients to modern WebSocket clients.
In any case, there is a trend towards HTTP client generation, instead of messing around with HTTP calls yourself. For that, you want to have a look at the OpenFeign project and its documentation as a starting point for further reading.
Which brokers are the best for asynchronous Java messaging?
Starting out with asynchronous messaging, you are likely going to end up with either ActiveMQ (Classic or Artemis), RabbitMQ or Kafka. Again, this is just a popular pick.
Here’s a couple of random points, though:
-
ActiveMQ and RabbitMQ are both traditional, fully fledged message brokers. This means a rather smart broker, and dumb consumers.
-
ActiveMQ historically had the advantage of easy embedding (for testing), which can be mitigated with RabbitMQ/Docker/TestContainer setups
-
Kafka is not a traditional broker. It is quite the reverse, essentially a relatively 'dumb' message store (think log file) needing smarter consumers for processing.
To get a better understanding on when to use RabbitMQ( or traditional message brokers in general) or Kafka, have a look at Pivotal’s matching blog post as a starting point.
In general, though, try to dismiss any artificial performance reasons when choosing your broker. There was a time when teams and online communities argued a ton about how fast RabbitMQ was and how slow ActiveMQ was.
Now you are having the same arguments on RabbitMQ being slow with just a consistent 20-30K/messages every.single.second. Kafka is cited with 100K messages/a second. For one, these kinds of comparisons conveniently leave out that you are, in fact, comparing apples and oranges.
But even more so: Both throughput numbers might be on the lower or medium side for Alibaba Group, but you author has never seen projects of this size (millions of messages every minute) in the real world. They definitely exist, but these numbers are nothing to worry about for the other 99% of regular Java business projects.
So, ignore the hype and choose wisely.
Which libraries can I use for microservice testing?
Depending on your stack you might end up using Spring specific tools (Spring ecosystem), or something like Arquillian (JavaEE ecosystem).
(Check out e.g. this course to get a deep dive into the Spring testing ecosystem,a ton of different testing libraries and the corresponding test-driven workflows. Note: I’m affiliated with the author.)
You’ll also want to have a look at Docker and the really good Testcontainers library, that helps you , for example, easily and quickly setup an Oracle database for your local development or integration tests.
For mocking out whole HTTP servers, have a look at Wiremock. For testing asynchronous messaging, try to embedding (ActiveMQ) or dockering (RabbitMQ) and then writing tests with the Awaitility DSL.
Note that this is by no means a comprehensive list and if you are missing your favorite tool, post it in the comments section and I’ll pick it up in the next revision of this guide.
How do I enable logging for all my Java microserviecs?
Logging with microservices is an interesting and rather complex topic. Instead of having one log file that you can less or grep, you now have n-log files, that you would like to see combined.
A great starting point for the whole logging ecosystem is this article. Make sure to read it, especially the Centralized Logging section in terms of microservices.
In practice, you’ll find various approaches:
-
A sysadmin writing some scripts that collect and merge log files from various server into one log file and put them onto FTP servers for you to download.
-
Run cat/grep/unig/sort combos in parallel SSH sessions. You can tell your manager: that’s what Amazon AWS does internally.
-
Use a tool like Graylog or the ELK Stack (Elasticsearch, Logstash, Kibana)
How do my microservices find each other?
So far, we kind of assumed that our microservices all know each other, know their corresponding IPS. More of a static setup. So, our banking monolith[ip=192.168.200.1] knows that he has to talk to the risk server[ip=192.168.200.2], which is hardcoded in a properties file.
You can, however, choose to make things much more dynamic:
-
You could not deploy application.properties files with your microservices anymore, instead use a cloud config server where all microservices pull their config from.
-
Because your service instances might change their locations dynamically (think of Amazon EC2 instances getting dynamic IPs and you elastic-auto-scale the hell out of the cloud), you soon might be looking at a service registry, that knows where your services live with what IP and can route accordingly.
-
And now since everything is dynamic, you have new problems like automatic leader election: Who is the master that works on certain tasks to e.g. not process them twice? Who replaces the leader when he fails? With whom?
In general terms, this is what’s called microservice orchestration and another huge topic by itself.
Libraries like Eureka or Zookeeper try to 'solve' these problems, like clients or routers knowing which services are available where. On the other hand, they introduce a whole lot of additional complexity.
Just ask anyone who ever ran a ZooKeeper setup.
How to do authorization and authentication with Java microservices?
Another huge topic, worth its own essay. Again, options range from hardcoded HTTPS basic auth with self-coded security frameworks, to running an Oauth2 setup with your own Authorization Server.
How do I make sure that all my environments look the same?
What’s true for non-microservice deployments is also true for microservice deployments. You will try a combination of Docker/Testcontainers as well as scripting/Ansible.
Try and keep it simple.
Not a question: Yaml Indentation Tales
Making a hard cut from specific library questions, let’s have a quick look at Yaml. It is the file format being used as the de-facto file format to 'write configuration as code'. From simpler tools like Ansible to the mighty Kubernetes.
To experience YAML indentation pain yourself, try and write a simple Ansible files and see how often you need to re-edit the file to get indentation working properly, despite various levels of IDE support. And then come back to finish off this guide.
Yaml:
- is:
- so
- greatWhat about Distributed Transactions? Performance Testing? Other topics?
Unfortunately, those topics didn’t make it in this revision of this guide. Stay tuned for more.
Conceptual Microservice Challenges
In addition to the specific Java microservice issues, there’s also issues that come with any microservice project. These are more from an organizational, team or management perspective.
Frontend/Backend Mismatch
Something that occurs in many microservice projects, is what I would call the frontend-backend microservice mismatch. What does that mean?
That in good old monoliths, frontend developers had one specific source to get data from. In microservice projects, frontend developers suddenly have n-sources to get data from.
Imagine you are building some Java-IoT microservices project. Say, you are surveilling machines, like industry ovens across Europe. And these ovens send you regular status updates with their temperatures etc.
Now sooner or later, you might want to be able to search for ovens in an admin UI, maybe with the help of a "search oven" microservices. Depending on how strict your backend colleagues might interpret domain driven design or microservice laws it could be that the "search oven" microservice only returns you IDs of ovens, no other data, like its type, model or location.
For that, frontend developers might have to do one or n-additional calls (depending on your paging implementation), to a "get oven details" microservice, with the ids they got from the first microservice.
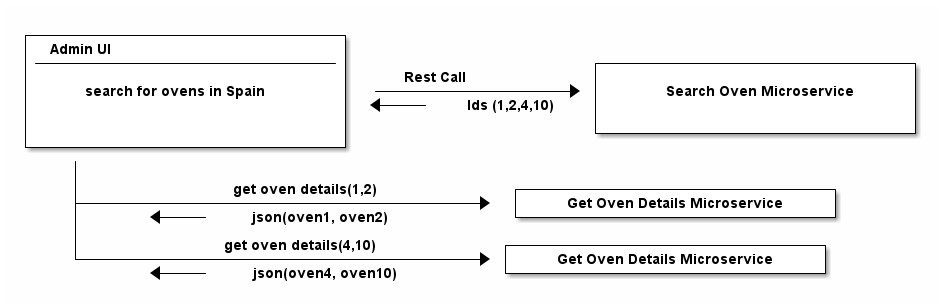
And while this only a simple (but taken from a real-life project(!)) example, it demonstrates the following issue:
Real-life supermarkets got huge acceptance for a reason. Because you don’t have to go to 10 different places to shop vegetables, lemonade, frozen pizza and toilet paper. Instead you go to one place.
It’s simpler and faster. It’s the same for frontend developers and microservices.
Management Expectations
This issue is something that is an unfortunate side-effect of individual developers, programming magazines or cloud companies pushing microservices:
Management having the impression that you now can pour in an infinite amount of developers into the (overarching) project, as developers can now work completely independent from each other, everyone on their own microservice. With just some tiny integration work needed, at the very end (i.e. shortly before go-live).

Let’s see why this mindset is such an issue in the next paragraphs.
Smaller pieces do not mean better pieces
One rather obvious issue is, that 20 smaller pieces (as in microservices) does not actually mean 20 better pieces. Purely from a technical quality perspective, it could mean that your individual services still execute 400 Hibernate queries to select a User from a database across layers and layers of unmaintainable code.
To go back to Simon Brown’s quote, if people cannot build monoliths properly, they will be having a hard time building proper microservices.
Especially resilience and everything that happens after the go-live is such an afterthought in many microservice projects, that it is somewhat scary to see the microservices running live.
This has a simple reason though: Because Java developers usually are not interested not trained properly in resilience, networking and other related topics.
Smaller pieces lead to more technical pieces
In addition, there’s the unfortunate tendency for user stories to get more and more technical (and therefore stupid), the more micro and abstracted away from the user they get.
Imagine your microservice team is asked to write a technical, login-against-a-database-microservice which is roughly this:
@Controller
class LoginController {
// ...
@PostMapping("/login")
public boolean login(String username, String password) {
User user = userDao.findByUserName(username);
if (user == null) {
// handle non existing user case
return false;
}
if (!user.getPassword().equals(hashed(password))) {
// handle wrong password case
return false;
}
// 'Yay, Logged in!';
// set some cookies, do whatever you want
return true;
}
}Now your team might decide (and maybe even convince businesspeople): That is way too simple and boring, instead of a login service, let’s write a really capable UserStateChanged microservice - without any real, tangible business requirements.
And because Java is currently out of fashion, let’s write the UserStateChanged microservice in Erlang. And let’s try to use red-black trees somewhere, because Steve Yegge wrote you need to know them inside-out to apply for Google.
From an integration, maintenance and overall-project perspective, this is just as bad as writing layers of spaghetti code inside the same monolith.
Fabricated and over-the-top example? Yes.
Unfortunately, also not uncommon in real-life.
Smaller pieces lead to smaller understanding
Then there’s this topic of understanding the complete system, its processes and workflows, if you as a developer are only responsible to work on isolated microservice[95:login-101:updateUserProfile].
It blends in with the previous paragraph, but depending on your organization, trust and communication levels, this can lead to a lot of shoulder-shrugging and blaming, if a random part of the whole microservice chain breaks down - with no-one accepting full responsibility anymore.
Not just insinuating bad faith, but the problem that it actually is really difficult to understand n-amount of isolated pieces and their place in the big picture.
Communication & Maintenance
Which blends in with the last issue here: Communication & Maintenance. Which obviously depends heavily on company size, with the general rule: The bigger, the more problematic.
-
Who is working on microservice number 47?
-
Did they just deploy a new, incompatible microservice version? Where was this documented?
-
Who do I need to talk to for a new feature request?
-
Who is going to maintain that Erlang microservice after Max left the company?
-
All our microservice teams work not only in different programming languages, but also in different time zones! How do we coordinate properly?
The overarching theme here is, that similarly to DevOps skills, a full-on microservices approach in a bigger, maybe even international company, comes with a ton of additional communication challenges. As a company, you need to be prepared for that.
Fin
Having read this article you might conclude that your author is recommending strictly against microservices. This is not entirely true - I am mainly trying to highlight points that are forgotten in the microservices frenzy.
Microservices are on a pendulum
Going full-on Java microservices is one end of a pendulum. The other end would be something like hundreds of good old Maven modules in a Monolith. You’ll have to strike the right balance.
Especially in greenfield projects there is nothing stopping you from taking a more conservative, monolithic approach and building fewer, better-defined Maven modules instead of immediately starting out with twenty, cloud-ready Microservices.
Microservices generate a ton of additional complexity
Keep in mind that, the more microservices you have, and the less really strong DevOps talent you have (no, executing a few Ansible scripts or deploying on Heroku does not count), the more issues you will have later on in production.
Reading through the Common Java Microservice Questions section of this guide is already exhausting. Then think about implementing solutions for all these infrastructure challenges. You’ll suddenly realize that none of this has to do with business programming anymore (what you are paid for), but rather with a fixation of more technology on even more technology.
Siva summed it up perfectly on his blog:
I can’t explain how horrible it feels when the team spends 70% of the time fighting with this modern infrastructure setup and 30% of the time on actual business logic.
Should you create Java microservices?
To answer that question, I’d like to end this article with a very cheeky, Google-like interview teaser. If you know the answer to this question by experience even though it seemingly has nothing to do with microservices, then you might be ready for a microservices approach.
Scenario
Imagine you have a Java monolith running solo on the smallest Hetzner dedicated machine. The same goes for your database server, it also runs on a similar Hetzner machine.
And let’s also assume that your Java monolith can handle workflows like user registrations and you do not spawn hundreds of database queries per workflow, but only a reasonable handful (< 10).
Question
How many database connections should your Java monolith (connection pool) open up to your database server?
Why? And to how many concurrently active users do you think your monolith can (roughly) scale?
Answer
Post your reply to these questions in the comment section. I’m looking forward to all answers.

Now, make up your own mind
If you are still here with me: Thanks for reading!
There's more where that came from
I'll send you an update when I publish new guides. Absolutely no spam, ever. Unsubscribe anytime.
Comments (read-only)
19 comments
Anonymous
July 11, 2023
You did not mention Microservice 12-factor principles. I think that was important.
Anonymous
April 27, 2023
Always a delight to read your blogs. Thx
Anonymous
September 30, 2022
Great article, this is my new microservice's bible :D
Anonymous
June 01, 2022
The article is awesome! Thank you, Marco!
But still, it seems for me too long to read it all. Probably it is much convenient to split it up.
But still, it seems for me too long to read it all. Probably it is much convenient to split it up.
Anonymous
October 08, 2021
Very informative about microservices. Thank you very much!
Anonymous
February 22, 2021
I am really glad I came across your blog. Great article! Thanks.
Anonymous
July 16, 2020
Good article. Just learn In old school monolith, exchanging data between 'module/object/services' within memory/cache/register as fast as raw electricity speed; Microservices is via TCP/IP network with many component in between. No wonder some commented on 30% productivity, 70% time having fun dealing with non-business logic. Thanks for sharing.
Anonymous
June 27, 2020
You came, you saw & you destroyed. Just killed it simply, Nobody explains it better than you on numerous blog posts or articles i have across till now. Please dont stop. You are like a god to someone like me, for explaining like the way you do in all your posts. Just keep going on and on. You might have no idea what a post like this can mean to someone who goes through numerous posts in a week on hot topics like these.
chennisubbra
May 22, 2020
thanks
getraajesh
January 21, 2020
Very Interesting. Great, Thanks. You have almost covered all the topics related to Microservices on a high level.
Anonymous
December 18, 2019
Good article, thank you for sharing, greetings from Spain!
Anonymous
December 15, 2019
Hi! Great article!
Spring's project oauth2 is now on maintenance mode, hence you should not create your own OAuth2 server anymore.
But, when do you know that is good to have a fully capable oauth2 server and not just an Authorization server that provides a simple jwt?
Spring's project oauth2 is now on maintenance mode, hence you should not create your own OAuth2 server anymore.
But, when do you know that is good to have a fully capable oauth2 server and not just an Authorization server that provides a simple jwt?
Anonymous
December 13, 2019
Very interesting, thank you.
Anonymous
December 13, 2019
I think you should mention about http timeout also. Most devs usually forget to set timeout.
Default library and Apache http client default timeout is infinite.
https://docs.oracle.com/javase/7/docs/api/java/net/URLConnection.html#setConnectTimeout(int)
Default library and Apache http client default timeout is infinite.
https://docs.oracle.com/javase/7/docs/api/java/net/URLConnection.html#setConnectTimeout(int)
Marco Behler
December 13, 2019
Very good point! Will add it in a future revision.
Anonymous
January 09, 2020
very nice article btw. sharing with my team.
Anonymous
December 13, 2019
Man at my previous company you would be crucified for such statements ;-)
Regarding the question at the end: it depends. It depends on how many registrations you have per hour let's say. How many concurrently active users can you handle? Well - registration is a one time action so the number of concurrently active users does not matter in this regard. But to give a number a give you 100 000 concurently active users :-)
Regarding the question at the end: it depends. It depends on how many registrations you have per hour let's say. How many concurrently active users can you handle? Well - registration is a one time action so the number of concurrently active users does not matter in this regard. But to give a number a give you 100 000 concurently active users :-)
Anonymous
December 13, 2019
Thanks, nice article
Anonymous
December 12, 2019
How many database connections should your Java monolith (connection pool) open up to your database server?
pool_size = ( cpu core count * 2 ) + effective spindle count
effective spindle count = 1 if SSD
pool_size = ( cpu core count * 2 ) + effective spindle count
effective spindle count = 1 if SSD
Marco Behler
December 13, 2019
We have a winner. That was too fast :)
Anonymous
July 27, 2020
For those of us of who are less knowledgable - could we get an explanation as to why this is the right answer?
Anonymous
December 12, 2019
Great article. I wish technical leadership (architects and managers) at my client would have considered some of these points.
I hope a future version of this article mentions the pain of dealing with legacy network infrastructure and cloud deployments. Proxy config, whitelisting IOS, firewall rules, etc.
Another fun topic is deploying to multiple environments and the configuration changes needed for each (local, QA, integration, prod validation, prod, ....)
Again, very well written article.
I hope a future version of this article mentions the pain of dealing with legacy network infrastructure and cloud deployments. Proxy config, whitelisting IOS, firewall rules, etc.
Another fun topic is deploying to multiple environments and the configuration changes needed for each (local, QA, integration, prod validation, prod, ....)
Again, very well written article.
Anonymous
December 12, 2019
Great article !

let mut author = ?
I'm @MarcoBehler and I share everything I know about making awesome software through my guides, screencasts, talks and courses.
Follow me on Twitter to find out what I'm currently working on.