
java -jar myNewAIStartup.jar
What is Kubernetes? An Unorthodox Guide for Developers
Last updated on February 10, 2024 -
Star me on GitHub →You can use this guide to get up to speed with Kubernetes as a developer. From its very basics to more intermediate topics like Helm charts and how all of this affects you as a dev.
(Editor’s note: At >5000 words, you probably don’t want to try reading this on a mobile device. Bookmark it and come back later.)
Introduction
If you’re a developer who has either never used Kubernetes before or wants to brush up on Kubernetes knowledge so that your DevOps colleagues will be scared positively surprised, this guide is for you.
Quick Question: Why is Kubernetes abbreviated to K8s?
Answer: It will magically reveal itself at the end of this guide, but only after you have fully read it. So, let’s not waste any more time.
How did we get here?
Many developers I’ve met throughout my career, didn’t necessarily care about the "now that I’ve written the code, it also needs to be run somewhere"-part of their application’s lifecycle. (Depending on how seriously your company defines and takes the word DevOps your mileage with this might vary).
But let’s start slowly. What does running an application actually mean?
It depends a bit on your programming language ecosystem. For example, in terms of Java and modern web applications, you literally compile all your sources in one, single, executable .jar file, that you can run with a simple command.
For production deployments, you typically also want some sort of properties, to set e.g. database credentials or other secrets. The easiest way in the above’s Java Spring Boot case would be to have an application.properties file, but you can also go crazy with external secret management services.
In any case, the command above is literally all you need to run to deploy your application - doesn’t matter if you’re deploying on bare metal, a VM, a Docker container, with or without Kubernetes, or maybe even your Java-powered toaster.
Running just one command can’t be it. Where is the catch?
Much has been written online about the issues that can arise when deploying your application:
-
What if there are library/OS/infrastructure/something version incompatibilities between my DEV environment and my PRD environment?
-
What if certain required OS packages are missing?
-
What if we don’t want deploy our application to a cloud service anymore, but a submarine?
Your mileage with these problems will vary a lot depending on what programming language ecosystem you’re using - a topic that is often ignored in online discussions.
With pure Java web applications, the issues mentioned above (excluding the submarine or more sensible infrastructure parts like your database), are, for a large part, non-issues. You install a JDK on a server/vm/container/submarine, run java -jar and live happily ever after.
With PHP, Python, ahem, Node the picture looks different and you could/can easily run into version incompatibilities across your dev, staging, or prod environments. Hence, people yearned for a solution to rid them of these pains: Containers.
Docker, Docker Compose & Swarm: A Recap
Hail to the Docker!
Chances are high that you already know what Docker is and how to work with it. (If not, and you want to see a Docker-specific guide, please post a comment down below! More demand → Faster publication). The short summary is:
-
You build your source code into a deployable, e.g. the
jarfile. -
You additionally build a new Docker image, with your
jarfile baked in. -
Said Docker image also contains all additional software and configuration options needed to be able to run successfully.
→ Instead of deploying your .jar file, you’ll now deploy your Docker image and run a Docker container.
The beauty of this is: That as long as you have Docker installed on the target machine (and you have kernel compatibility between your host OS and the Docker container) you can run any Docker image you want.
docker run --name my-new-ai-startup -p 80:8080 -d mynewaistartup
// yay, your application is deployed
// This will start a Docker container based on the `_mynewaistartup_` Docker image.
// That image will, that other things, contain your e.g. -jar file,
// a web application which runs on port 8080, as well as instructions on how to run it.
// Hint: These instructions are `_java -jar mynewaistartup.jar_`.What does 'deploying' Docker images mean?
You or your CI/CD server managed to bake your application into a Docker image. But how does that Docker image eventually end up on your target deployment server?
You could theoretically save your Docker image as a .tar file, copy it onto your final server, and load it there. But more realistically, you’d push your Docker image to a Docker registry, be that dockerhub, Amazon ECR or any of the other gazillion self-hosted container registries, like GitLab’s, for example.
Once your image made it to said registry, you can login to that registry on your target server.
docker login mysupersecret.registry.comAnd once you are logged in to your registry, your docker run will be able to find your custom images.
docker run --name my-new-ai-startup -p 80:8080 -d mynewaistartup
//....
SUCCESS!Docker Compose: Running more than one container simultaneously
What if your application consists of more than just a single Docker container, say, because you need to run 98354 microservices?
Docker Compose to the rescue. You’ll define all your services and the dependencies between them (run this one or the other one first) in a good, old, YAML file, a compose.yaml. Here’s an example of such a file, defining two services, a web service and a Redis service.
services:
web:
build: .
ports:
- "8000:5000"
volumes:
- .:/code
- logvolume01:/var/log
depends_on:
- redis
redis:
image: redis
volumes:
logvolume01: {}Then you just run docker compose up and your whole environment (consisting of all your separate services running in separate docker containers) will be started. Do note, that this means all your containers will run on the same machine. If you want to scale this out to multiple machines, you’ll need to use Docker Swarm.
While Docker Compose might be mainly known for quickly spinning up development or testing environments, it actually works well for (single host) prod deployments as well.
If your application…
-
doesn’t have any specific high-availability requirements
-
you don’t mind some manual work (ssh login, docker compose up/down) or using a complementary tool like Ansible
-
or you simply don’t want to spend enormous amounts of money investments on a DevOps team
…using Docker Compose for production deployments will go a long way.
Kubernetes 101: Basics & Concepts
What do I need Kubernetes for, then?
Things get interesting if you want to start running hundreds, thousands (or a multiple of that) containers. And if you don’t care or don’t want to know what specific underlying hardware/box these containers will be running on, yet still want to be able to sensibly manage all of this. Kubernetes, to the rescue!
(Note: Quite a while ago I read a Kubernetes book, where in the intro they specified a lower-bound number where running Kubernetes starts makes sense and I think it started with hundreds to thousands, though I cannot find the exact book anymore.)
Let’s do a quick Kubernetes Concept 101.
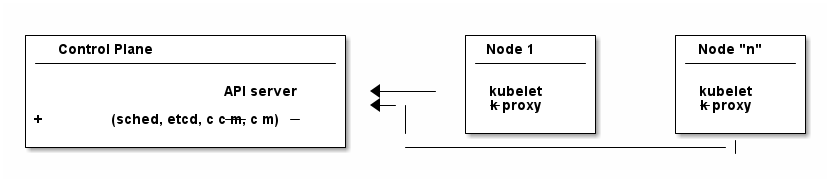
(Worker) Nodes
Your software (or workload in Kubernetes terms) has to run somewhere, be it a virtual or physical machine. Kubernetes call this somewhere Nodes.
Furthermore, Kubernetes deploys and runs containers: Hello, Docker, my old friend! (Note: Kubernetes supports many container runtimes, from containerd, CRI-O, Docker Engine and more, though Docker is the most commonly used)
Actually, this is not 100% right. In Kubernetes' terms, you deploy (schedule) Pods, with a pod consisting of one or more containers.
Alright, we got pods running on nodes, but who controls those nodes and how and where do you decide what to run on these nodes?
(TIP: A tiny mapping table)
| Non-Kubernetes → | Kubernetes Speak |
|---|---|
Software/Application(s) |
Workload |
Machine |
Node |
(1-many) Container(s) |
Pod |
Deployment |
Scheduling |
Control Plane
Meet the Control Plane. For simplicity’s sake, let’s just think of it as one component that controls your nodes (as opposed to the approximately 9472 components it consists of). The control pane, among many things,…
-
Lets you run schedule your application, i.e. lets you put a pod on a node.
-
Checks if all your pods are in the desired state, e.g. are they responsive, or does one of them need to be restarted?
-
Fulfills every engineer’s fantasy: "We need to finally scale 10xfold, let’s quickly spin up n-more pods!"
Pods vs Nodes
In case the difference between pods and nodes is still a bit unclear. Kubernetes has a so-called Scheduler. Whenever the Scheduler discovers new pods (== container(s)) to be scheduled (yay!), it tries to find the optimal node for the pod. This means it could very well be the case that multiple pods run on the same node or different ones. If you want to dig deeper into this topic, you might want to read the documentation for "node selection" and how you can influence it, in the official documentation.
Clusters & Clouds
Take multiple nodes and your control pane, and you have a cluster.
Take multiple clusters and you can separate your dev, test & production environments or maybe teams, projects or different application types - that’s up to you.
Take it even further, and try going go multi-cloud Kubernetes, running multiple clusters across different private and/or public cloud platforms (Congratulations! What you have achieved is not for the faint of heart.)
Addons
There are also a fair amount of Kubernetes add-ons.
Most importantly for developers, there is a Web UI/Dashboard which you can use to essentially manage your cluster.
If you’re not self-hosting your Kubernetes setup, you’d simply use whatever UI your cloud vendors, like Google Cloud, AWS or the many others provide.
Please, let’s stop with the Kubernetes 101
Those four 101 sections above will (hopefully) give you enough of a mental model to get started with Kubernetes and we’ll leave it at that with the concepts.
Truth be told, you’ll be shocked if you enter "Kubernetes" on https://learning.oreilly.com . You’ll get thousands of learning resource results, with many many many of the books being 500+ pages long. Fine reading for a rainy winter day! The good part: you, as a developer, don’t have to care about most of what’s written in these books, teaching you how to set up, maintain and manage your clusters, though being aware of the sheer complexity of all of this helps.
What do I need to do to see all of this in action?
-
A Kubernetes installation (we’ll talk about that a bit later in more detail)
-
YAML, YAML, YAML!!!
-
A tool to interact with your Kubernetes cluster:
kubectl
Where do I get kubectl?
You can download kubectl, which is essentially the CLI tool to do everything you ever wanted to do with your Kubernetes cluster here. That page lists various ways of installing kubectl for your specific operating system.
How do I pronounce kubectl?†
See https://www.youtube.com/watch?v=9oCVGs2oz28. It’s being pronounced as "Kube Control".
What do I need for kubectl to work?
You’ll need a config file, a so-called kubeconfig file, which lets you access your Kubernetes cluster.
By default, that file is located at ~/.kube/config. It is also important to note that this config file is also being read in by your favorite IDE, like IntelliJ IDEA, to properly set up its Kubernetes features.
Where do I get the kubeconfig file from?
Option 1 If you are using a managed Kubernetes installation (EKS, GKE, AKS), check out the corresponding documentation pages. Yes, just click the links, I did all the work linking to the correct pages. Simply put, you’ll use their CLI tools to generate/download the file for you.
Option 2 If you installed e.g. Minikube locally, it will automatically create a kubeconfig file for you.
Option 3 If you happen to know your Kubernetes master node and can ssh into it, run a:
cat /etc/kubernetes/admin.conf or cat ~/.kube/config
Anything else I need to know about the kubeconfig file?
A kubeconfig file consists of good, old YAML, and there are many things it can contain (clusters, users, contexts). For the inclined, check out the official documentation.
For now, we can ignore users and contexts and live with the simplification that the kubeconfig file contains the cluster(s) you can connect to, e.g. development or test.
Here’s an example kubeconfig file, taken from the official Kubernetes documentation.
(Don’t worry, you don’t have to understand this line-by-line, it’s simply there to give you a feeling of what these files look like)
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
- cluster:
insecure-skip-tls-verify: true
server: https://5.6.7.8
name: test
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: test
namespace: default
user: experimenter
name: exp-test
current-context: ""
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
- name: experimenter
user:
# Documentation note (this comment is NOT part of the command output).
# Storing passwords in Kubernetes client config is risky.
# A better alternative would be to use a credential plugin
# and store the credentials separately.
# See https://kubernetes.io/docs/reference/access-authn-authz/authentication/#client-go-credential-plugins
password: some-password
username: expKubectl 101
What can you now do with Kubectl? Remember, at the beginning, we said your goal is to have a pod (n+ containers), and schedule it (run them) on a node (server).
The way is to feed yaml files (yay) with the desired state of your cluster into kubectl, and it will happily set your cluster into the desired state.
Pod Manifests
You could, for example, create a file called marcocodes-pod.yaml that looks like this…
apiVersion: v1
kind: Pod
metadata:
name: marcocodes-web
spec:
containers:
- image: gcr.io/marco/marcocodes:1.4
name: marcocodes-web
ports:
- containerPort: 8080
name: http
protocol: TCP…and feed it into your Kubernetes cluster with the following kubectl command:
kubectl apply -f marcocodes-pod.yamlWhat would applying this yaml file do? Well, let’s go through it step by step:
kind: PodKubernetes knows a variety of so-called objects, Pod being one of them, and you’ll meet the other ones in a bit. Simply put, this .yaml file describes what pod we want to deploy.
metadata:
name: marcocodes-webEvery object and thus every .yaml file in Kubernetes is full of metadata tags. In this case, we give our pod the name with the value marcocodes_web. What is this metadata for?
Simply put, Kubernetes needs to somehow, uniquely identify resources in a cluster: Do I already have a pod with the name marcocodes_web running or do I have to start a new one? That is what the metadata is for.
spec:
containers:
- image: gcr.io/marco/marcocodes:1.4
name: marcocodes-web
ports:
- containerPort: 8080
name: http
protocol: TCPYou need to tell Kubernetes what your pod should look like. Remember, it can be n+ containers, hence you can specify a list of containers in the YAML file, even though often you only specify exactly one.
You’ll specify a specific Docker image, including its version and also expose port 8080 on that container via http. That’s it.
What REALLY happens to this yaml file?
Long Story Short When you then run kubectl apply, your yaml file will be submitted to the Kubernetes API Server and eventually our Kubernetes system will schedule a pod (with a marcocodes 1.4 container) to run on a healthy, viable node in our cluster.
More technically, Kubernetes has the concept of a reconcilliation loop, a fancy term for the scheduler being able to say:
"Here is my current Kubernetes cluster state, here is the users' yaml file, let me reconcile these two". User wants a new pod? I’ll create it. User wants storage? I’ll attach it to the container, etc.
Speaking about storage…
Resources & Volumes
Specifying just the container image isn’t all you can do. First off, you might want to take care of your container’s resource consumption:
# ....
spec:
containers:
- image: gcr.io/marco/marcocodes:1.4
resources:
requests:
cpu: "500m"
memory: "128Mi"
# ....This makes sure your container gets at least 500m (aka 0,5) of CPU, and 128 MB of memory. (You can also specify upper limits that are never to be broken).
In addition, when a Pod is deleted or a container simply restarts, the data in the container’s filesystem is deleted. To circumvent that, you might want to store your data on a persistent volume.
# ....
spec:
volumes:
- name: "marcocodes-data"
hostPath:
path: "/var/lib/marcocodes"
containers:
- image: gcr.io/marco/marcocodes:1.4
name: marcocodes
volumeMounts:
- mountPath: "/data"
name: "marcocodes-data"
ports:
- containerPort: 8080
name: http
protocol: TCP
# ....We’re going to have one volume called marcocodes-data, which will be mounted to the /data directory on the container, and live under /var/lib/marcocodes on the host machine.
Where’s the catch?
You just learned that there are pods, and they consist of one or more Docker images, as well as resource consumption rules and volume definitions.
With all of that YAML we then managed to schedule a single, static, one-off pod. Cheeky question: Where is the advantage over just running docker run -d --publish 8080:8080 gcr.io/marco/marcocodes:1.4?
Well, for now, there actually is none.
That’s why we need to dig deeper into the concepts of ReplicaSets and Deployments.
ReplicaSets
Let’s be humble. We don’t need auto-scaling right off the bat, but it would be nice to have redundant instances of our application and some load-balancing, to be a bit more professional with our deployments, wouldn’t it?
Kubernetes' ReplicaSets to the rescue!
Let’s have a look at a marcocodes-replica.yaml file, that defines such a minimal ReplicaSet.
apiVersion: apps/v1
kind: ReplicaSet
# metadata:
# ...
spec:
replicas: 2
selector: "you will learn this later"
# ...
template:
metadata: "you will learn this later"
# ...
spec:
containers:
- name: marcocodes-web
image: "gcr.io/marco/marcocodes:3.85"I left a fair amount of lines (and complexity) out of this YAML file, but most interestingly for now are these two changes:
kind: ReplicaSetThis .yaml now describes a ReplicaSet, not a Pod anymore.
spec:
replicas: 2Here’s the meat: We want to have 2 replicas == pods running at any given time. If we put in 10 here, Kubernetes would make sure to have 10 pods running at the same time.
When we now apply this .yaml file….
kubectl apply -f marcocodes-rs.yamlKubernetes will fetch a Pod listing from the Kubernetes API (and filter the results by metadata) and depending on the number of pods being returned, Kubernetes will spin up or down additional replicas. That’s all there is to it.
ReplicaSets: Summary
ReplicaSets are almost what you’d like to have, but they come with a problem: They are tied to a specific version of your container images (3.85 in our case above) and those are actually not expected to change. And ReplicaSets also don’t help you with the rolling out process (think, zero downtime) of your software.
Hence we need a new concept to help us manage releases of new versions. Meet: Deployments.
Deployments
Meet Deployments, which are used to manage ReplicaSets (wow!).
apiVersion: apps/v1
kind: Deployment
metadata: "ignore for now"
# ...
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector: "ignore for now"
# ...
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
"ignore for now"
# ...There are an additional 92387 YAML key-value pairs you’ll need to learn for Deployments, and we’re already quite long into this article. The gist of it is: Kubernetes allows you to have different software rollout strategies (rollingUpdate or recreate).
-
Recreate will kill all your pods with the old version and re-create them with a new version: your users will experience downtime
-
RollingUpdate will perform the update while still serving traffic through old pods, and is thus generally preferred.
The Static Nature of K8s
Do note, that everything you have seen so far is, essentially, static. You have YAML files, and even with the Deployment objects above, if you have a new version of your container, you need to edit the .yaml file, save it and apply it - there is a fair amount of manual work involved.
If you want things to be a bit more dynamic, you’ll have to additional tools such as https://helm.sh/, which we’ll discuss below.
Rolling Updates: Too Good To Be True
While we are talking about deploying new versions of your containers….
As always, the devil is in the details. Rolling updates have been done many moons ago already before Kubernetes existed, even if it was just batch scripts firing SSH commands.
The issue, bluntly put, is not so much about being able to shut down and spin up new instances of your application, but that for a short while (during the deployment) your app essentially needs to gracefully support two versions of the application - which is always interesting as soon as a database is involved or if there have been major refactorings in APIs between frontend/backend, for example.
So, beware of the marketing materials, selling you easy rolling updates - their real challenge has nothing to do with Kubernetes.
Side-Note: Self-Healing
On a similar note, that same is true for the term self-healing. What Kubernetes can do, is execute health checks and then take an unresponsive pod, kill it, and schedule a new one. That is also functionality, which has in one form or another existed endlessly. Your favorite Linux distro has essentially always been able to watch and restart services through a variety of ways - albeit limited to the current machine.
What Kubernetes cannot do is automatically take a botched database migration, which leads to application errors, and then magically self-heal the cluster, i.e. fix corrupted database columns.
It is just my impression that talk about self-healing systems often insinuates the latter (maybe among management), whereas it is much more basic functionality.
Service Discovery, Load Balancing & Ingress
So far, we talked about dynamically spawning up pods, but never about how network traffic actually reaches your applications. Kubernetes is inherently dynamic, meaning you can spawn new pods or shut them down at any point in time.
Kubernetes has a couple of concepts to help you with that, from Service objects (which allow you to expose parts of your cluster to the outer world) to Ingress objects (allowing you to do HTTP load balancing). Again, this will amount to tons and tons of YAML and a fair amount of reading, but at the end of the day Kubernetes allows you to route any traffic your application gets to your cluster and the other way around.
(Fun Ingress Fact: You’ll need to install an Ingress controller (there is no standard one being built into Kubernetes), which will do the load-balancing for you. Options are plenty: On platforms like AWS, you’d simply use ELB, if you go bare-metal Kubernetes you could use Contour, etc.)
Last but not least: ConfigMaps & Secrets Management
Apart from the myriad things you’ve already seen Kubernetes do, you can also use it to store configuration key-value pairs, as well as secrets (think database or API credentials).
(By default, secrets are being stored unencrypted, hence the need to follow the Safely use Secrets section on this page, or even altogether plugging in an external Secrets store, from AWS, GCP’s and Azure’s solutions, to HashiCorp’s Vault.)
Enough! Don’t these YAML files become a mess?
Well…
If you think of deploying e.g. Wordpress with Kubernetes, then you’ll need a Deployment, as well as a ConfigMap and probably also Secrets. And then a couple of other Services and other objects we haven’t touched here yet. Meaning, you’ll end up with thousands of lines of YAML. This doesn’t make it intrinsically messy, but already at that small stage, there is a ton of DevOps complexity involved.
However, you’re also a developer and hopefully not necessarily the one maintaining these files.
Just in case you have to, it helps tremendously to use your IDEs Kubernetes' support, IntelliJ IDEA in my case, to get coding assistance support for Helm charts, Kustomize files et al. Oh, we haven’t talked about them yet. Let’s do that. Here’s a video, which will get you up to speed with IntelliJ’s Kubernetes Plugin.
Kubernetes: Additional Topics
What is Helm? What are Helm Charts?
You can think of Helm as a packager manager for Kubernetes. Let’s get a few concepts down:
As we mentioned above, 'just' installing Wordpress in a Kubernetes cluster will lead to thousands of YAML lines. And it would be great if you didn’t have to write those YAML lines yourself, but could use a pre-built package for that, replacing a couple of variables along the way for your specific installation.
That is what Helm Charts are, a bunch of YAML files and templates, laid out in a specific directory structure. When you then go about installing a specific chart, Helm will download it, parse its templates and along with your values generate good old Kubernetes YAML files/manifests, that it then sends to you Kubernetes.
Here is what a tiny snippet of one such template file (for a Deployment manifest) could look like, including a couple of placeholders:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "myChart.name" . }}
labels:
{{- include "myChart.labels" . | nindent 4 }}You can then take these charts and share them through repositories. There is no single, default chart repository. A good place to find popular chart repositories is https://artifacthub.io/.
In short, your workflow with Helm would be:
-
Install a chart of your liking - Part 1
helm install my-release oci://registry-1.docker.io/bitnamicharts/wordpressThis line would install the
wordpresschart from the popular bitnami chart repository into your cluster, the end result: A running wordpress installation. In case you are wondering what OCI is: You can host Helm charts in container registries (Amazon ECR, Docker Hub, Artifactory etc…) that support the Open Containers Initiative standard. -
Install a chart of your liking - Part 2
As you almost always will have some configuration values to override (check out the immense list of parameters in the Wordpress case here), you’ll want to provide your specific values to the install command. Which you can do through a YAML file, conventionally named
values.yamlor directly with a command line flag. So, the install command would rather look like this:helm install my-release oci://registry-1.docker.io/bitnamicharts/wordpress --values values.yaml // OR helm install my-release oci://registry-1.docker.io/bitnamicharts/wordpress --set wordpressUsername=m4rc0 // etc... -
Note: You can also use helm to upgrade your installations. Either, upgrade to a newer version of your chart (think new release), or upgrade the configuration of your installation, with the help of the
helm upgradecommand.
If you want to get deeper into helm, I can only recommend you the wonderful Learning Helm book.
What is Kustomize?
You learned above that Helm uses templates to generate Kubernetes manifests. That means someone needs to do the work to create Helm templates out of Kubernetes manifests, maintain them and then you as the end-user can use the helm command line client to apply them.
The developers of Kustomize wanted to go down a different route: It allows you to create custom versions of manifests by layering your additional changes on top of the original manifest. So, instead of creating templates and "placeholdering" them, you’d end up with a file structure e.g. like this:
├── deployment.yaml // your original Kubernetes manifest filef
└── kustomization.yaml //
// (in more relalistic scenarios, you'deven have 'overlays' subfolders for different environments, like development/staging/prod etcYou would then run` kustomize build`, so that Kustomize applies your overlay and renders the final YAML result, which you can directly feed into the kubectl command (or directly run kubectl apply -k)
kustomize build . | kubectl apply -f -If you want to understand how a kustomization.yaml file needs to be structured, have a look here.
Which is better: Helm or Kustomize?
Don’t we all love opinions on Reddit? Enjoy: https://www.reddit.com/r/kubernetes/comments/w9xug9/helm_vs_kustomize/.
What is Terraform and what is the difference to Kubernetes?
Thank god we’re nearing the end of this guide and I don’t have to spend another thousand words on Terraform (hint: as always, you’ll find plenty of books and learning resources on Terraform alone out there), so I’ll try and make this short:
Kubernetes is about container orchestration. "Let me tell you what I want in this YAML file: Take my container(s) and run them somewhere for me!"
Terraform is about provisioning infrastructure: "Let me tell you what I want in these HashiCorp Configuration Language (HCL, .tf) files! Please create five servers, a couple load balancers, two databases, a couple queues, as well as monitoring facilities in e.g. the cloud of my choice." Or: "Please set up these Kubernetes clusters (EKS) on AWS for me".
How do I do local development with Kubernetes?
For local development, you essentially have two choices.
You could run a local Kubernetes cluster and deploy your application(s) into it. You’d probably use Minikube for that. And because the whole "my application changed - now let’s build a container image - and then let’s deploy this into my cluster" is rather cumbersome to be done manually, you’ll probably also want to use a tool like Skaffold to help you with this. Have a look at this tutorial to get started with that workflow. While this setup works, it comes with a fair amount of complexity and/or resource consumption.
This is where the workaround, choice number two, comes in. For local development, you’d essentially ignore Kubernetes and clone whatever config you need into your very own docker-compose.yml file and simply run that. A much simpler setup, but it comes with the downside of having to maintain two sets of configurations (docker-compose.yml + your K8s manifest files).
If you are already using Kubernetes, please let me know in the comment section down below how you approach local development.
Do I really need all of this?
It’s a good question and it would be the perfect time to sprinkle in some real-life K8s anecdotes: Sysadmins resource constraining pods to death, so that booting up pods takes forever - so long that they are being marked unhealthy and killed, leading to an endless pod-creation-killing loop, but we’ll save the long explanation for another time.
As a developer you usually don’t have the choice to decide, but here’s the big picture:
As mentioned earlier in the article, there is an endless amount of learning material when it comes to just 'hosting' a Kubernetes cluster and we’re not just talking about 'self-hosting' on bare metal, but also using any of the managed Kubernetes variants. If you have the in-house expertise to:
-
handle all this additional complexity
-
you can explain all the concepts described in this article in more and better detail to all of your developers
-
AND FIRST AND FOREMOST you have legitimate requirements to manage hundreds and thousands of containers dynamically (and no, magic out-of-the-blue-scaling requirements don’t count)
-
go for Kubernetes. But it is my belief that a huge amount of companies could save themselves a fair amount of time, money & stress with a simpler approach, instead of fantasizing about having Google scale infrastructure challenges.
-
Common Kubectl Commands
If there is any interest in kubectl commands that developers might need, post a comment down below, and I’ll add the most frequently used here, as a neatly grouped/sorted list.
Why is Kubernetes abbreviated K8s
I thought you might have forgotten by now! Here’s a quote taken straight from Kubernetes' documentation:
"The name Kubernetes originates from Greek, meaning helmsman or pilot. K8s as an abbreviation results from counting the eight letters between the "K" and the "s". Google open-sourced the Kubernetes project in 2014"
Fin
By now, you should have a pretty good overview of what Kubernetes is all about. Feedback, corrections and random input are always welcome! Simply leave a comment down below.
Thanks for reading.
Plan For The Next Revision
Vote in the comment section if you want any of the below or all of them to happen:
-
Supply copy-paste commands * K8s files so that readers can follow along
-
Potentially: Kubectl Commands
-
Potentially: Example on Kubernetes vs Docker Compose side-by-side configs
-
Potentially: GitOps
-
Suggestion: Connecting to Kubernetes using Kubectl/K9s/Lens IDE or IntelliJ Kubernetes Plugin
-
Suggestion: Service Mesh using Istio - common use-case when working with microservices.
Acknowledgments & References
Thanks to Maarten Balliauw, Andreas Eisele, Andrei Efimov, Anton Aleksandrov, Garth Gilmour, Marit van Dijk, Paul Everitt, Mukul Mantosh for comments/corrections/discussion. Special thanks to the authors of Getting Started with Kubernetes, as well as Learning Helm.
There's more where that came from
I'll send you an update when I publish new guides. Absolutely no spam, ever. Unsubscribe anytime.
Comments

let mut author = ?
I'm @MarcoBehler and I share everything I know about making awesome software through my guides, screencasts, talks and courses.
Follow me on Twitter to find out what I'm currently working on.